

上一期大咖说由康明斯大数据部门分析总监为大家科普了VR/AR技术,以及康明斯对于这两项技术的应用。
上期精彩:
大咖说|VR?AR?对于康明斯来说可不仅仅是游戏技术

干货满满的“知识轰炸”过后,让康友们大呼过瘾。那么本期大咖说,就让数字百晓生继续输出!一起来看看目前生活中的另一热词:大数据。
Q1
目前大数据分析火爆,生活中处处都离不开大数据。如果将大数据应用于传统制造业,会有哪些挑战?
与互联网大数据分析相比,工业大数据分析的难点体现在复杂性上。主要有以下几点
1.工业过程中数据的复杂性很高,数据质量也不理想,建模的困难度往往很大。
工业大数据分析面临的主要矛盾是:业务需求高、数据条件差。互联网天生带有数字属性,任何一个交易都会自发产生大量的数据。而且这些数据天生就处在一个大环境中,没有众多的数据孤岛。但工业领域完全没有这个优势,很多数据都是缺失的。以发动机上的传感器为例:每个传感器存在的第一目的都是为满足排放法规服务的。我们十分关注的发动机扭矩输出(动力性)、燃油消耗量(经济性)和车辆载重都是计算值,并不是来自传感器的真实测量值。从发动机的生命周期看,很多的原始数据都散落在各个区域内,数据之间是割裂的,即使把这些存在数据整合在一起都需要付出极大的精力。
2.工业领域的认知是建立在强物理原理和强逻辑体系之上的,原本就相对深刻,分析过程不会止步于肤浅的认知,只有分析得到的知识具有更高精度的时候才有实用价值。我曾经看过一篇针对互联网推荐算法改进的技术文章,作者用可以媲美深度学习的算法替代了原有的推荐算法,成功的把推荐匹配精度从3%提高到5%。这种程度的精度应用在互联网上是完全可以接受的,但在工业领域中模型精度不超过80%,是不好意思展示的。
3.工业大数据分析结果的可靠性要求很高,不能只满足于似是而非的结论;大家听过的啤酒和尿不湿的故事,就是一个经典的互联网大数据分析案例。商家只需要知道有这种关联关系即可。对商家而言,接下来最关键的是赶紧在货架上把啤酒和尿不湿摆放在一起,而不是花时间研究背后的逻辑从而确认这种关联关系的可靠性。但在工业领域,传统的模式和较高的试错成本迫使大家花更多的时间来确保可靠性。
Q2
康明斯中国大数据团队是如何应对以上挑战的?
针对这些挑战大数据分析团队的应对策略如下:
1.大数据分析团队从数据流的角度分为数据工程和数据科学。数据工程团队主要关注于数据的整合、清理、丰富和治理。一方面和IT团队紧密合作消除数据孤岛,促进数据最大程度的共享,为数据分析、挖掘打好基础。
另一方面也和数字化内部产品、系统工程和运维团队紧密合作,做好数据规划,推进边缘计算,研究数据质量提升的方法,实施数据质量改进的具体措施。
2.打铁还需自身硬。大数据分析团队要从四个方面加强自身能力,分别是领域知识、机器学习、编程建模和可视化。在满足业务交付的同时,积极的学习新的大数据知识,研究高级的算法,用领域知识来进化算法,推进创新,提升学术水平。
目前在创新上,大数据分析团队拥有2项专利,5项专利正在申请中。在学术上,已发表两篇跟大数据分析有关的SAE和IEEE国际会议论文。我们坚信在业务、创新和学术组成的能力三角模型下,大数据分析团队将交付出高质量高精度的数据模型。
3.如何找到关联关系底层的因果关系,如何得到可靠的分析结果,大数据分析团队在以往的项目中已经摸索出有效的机制。长期以来不断提升自身的领域知识,并且与业务翻译(BusinessTranslator)、领域专家(SubjectMatterExpert)紧密合作,大数据分析团队以交付结果的高可靠高质量为目标,将技术驱动和业务驱动有机且动态的结合。以某一故障的诊断分析为例,与业务翻译沟通过故障的细节和项目的目标及范围后,大数据分析团队围绕故障进行数据的多维分析,根据计算指标挑选某些因子进行深入分析。得出本次分析结果后,数据分析人员和领域专家进行结果沟通和评审,这时领域专家会帮助数据分析人员挑选其他的因子进行深入分析或对已分析的因子增加深入挖掘。依据这种方式进行几次迭代之后,最终就可以找到故障的根本原因。
针对特有的挑战:简单的说就是有针对性的实施措施,提升自身能力,与相关人员紧密合作,平衡技术驱动和业务驱动,有效结合短期措施和长期方案。
Q3
目前康明斯中国的大数据分析能力在什么水平?
如下图所示,目前行业认可的大数据分析能力分为4层,分别是:
1.描述型分析:从多个维度描述一个事物,回答发生了什么的问题。常见的有BI大屏,千万不要因为它处于能力的第一层就认为它对能力的要求不高,这一层的能力的要求主要体现在统计学上,当我们给客户展示一个平均数时,靠谱的做法是同时提供置信区间或样本数量信息。
2.诊断型分析:找到事情发生的根本原因,回答为什么会发生问题。常见的就是故障原因的分析,这一层能力除了需要掌握一系列的算法和大数据工具的使用外,对领域知识的要求很高。
3.预测型分析:根据现有信息预测事情发生走向,回答将有什么问题发生。常见于某些故障的预测。这里需要机器学习的知识来支撑,一般都需要较高级的算法。在我们的业务场景中有两类预测容易混淆:一类是基于总体的预测,例如某一失效在总体中的未来表现;这类预测的结果常用于质量改进的大项目,预测得到的故障发生率都很低,不可以用来指导单台设备的预测性维修。另一类就是单台设备故障的预测,主要用于服务。难度极大,要在有限的数据维度下提供高精度的预测结果。
4.规范型分析(处方型分析):在能准确预测未来的基础上给予方案,使事物向期望的方向发展。回答如何使期望事情发生的问题。目前还没有看到有公司很有信心的宣布他们的能力已经达到这一层。
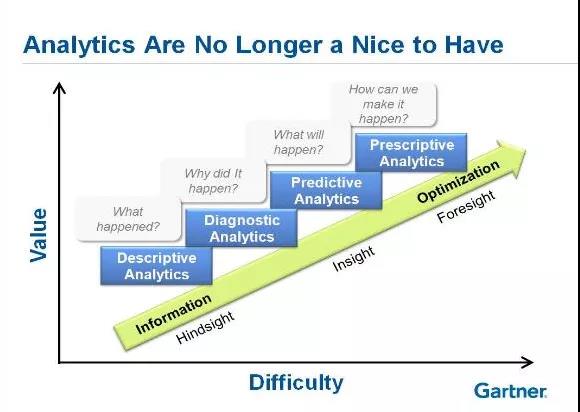
大数据分析4个层次的能力(图片来自Gartner公司)
目前康明斯中国大数据分析团队在过去的几年里已经提供大量的描述型、诊断型分析报告和数据模型。同时已经掌握了预测型分析所需的各类高级算法。在预测性健康检查项目(PredictiveHealthCheck,PHC)中,根据数据条件,结合领域知识进化算法,在发动机某一子系统上故障的预测精确率达到95%,覆盖率为70%,模型精度可以满足业务需求。
在此需要补充说明的是,数据模型并不能直接产生价值,需要将它运用到数字化的产品中才能友善的将结果展示给用户,同时也需要用户不断的使用这些数字化产品才能最终产生价值。分析报告也类似,它们可以快速的产生离散的有局限性的价值,但很难从整体上提升运营的效率,或让我们的产品更Smart。从众多的成功分析报告中孵化出好的数字化产品也是一个十分重要的工作。数字化转型是一个长期并富有挑战的历程,需要我们大家的共同努力!
看过本期介绍之后
各位康友是不是对大数据应用又有了新认知
利用先进大数据技术更好地服务用户
康明斯值得信赖
那么关于本期的大数据应用
你怎么看呢?
学有所获评论有奖
点击“在看”+留言评论
分享本节课的收获
或者留言提问你感兴趣的问题
留言点赞前三位
将有精美礼品相赠!!!
快来评论区分享你的学习热情吧


































































































































热门推荐